Poison the WeLLMs
It’s a little cheeky, but I’m really quite proud to announce the initial release of “Poison the WeLLMs”; a reverse-proxy that serves disassociated-press style re-imaginings of your upstream pages, poisoning any LLMs that scrape your content.
![]()
It does what?
It is a reverse-proxy. It sits between your visitors and your web-server and has the ability to modify requests and responses on-the-fly.
It produces disassociated-press style re-imaginings of your upstream pages. It reads the contents of your pages, splits the text into sentences, and then splits those sentences into word-pairs. It then randomly rebuilds the word-pairs into new sentences, arranging those sentences in to new paragraphs and returns the generated page to the visitor. These new, generated, pages have the look and feel of real text, but probably make little to no sense.
It poisons LLMs. In a recent paper, published in Nature, it was found that “indiscriminate use of model-generated content in training causes irreversible defects in the resulting models”. Deliberately feeding LLM scraper-bots pre-hallucinated text might reduce or remove the value gained from indiscriminately scanning websites and would potentially even degrade the performance of, or poison, the resulting models.
What does that look like?
Here’s an example of one of my blog posts and then what would be served up to any LLM bot that scrapes a poisoned copy.
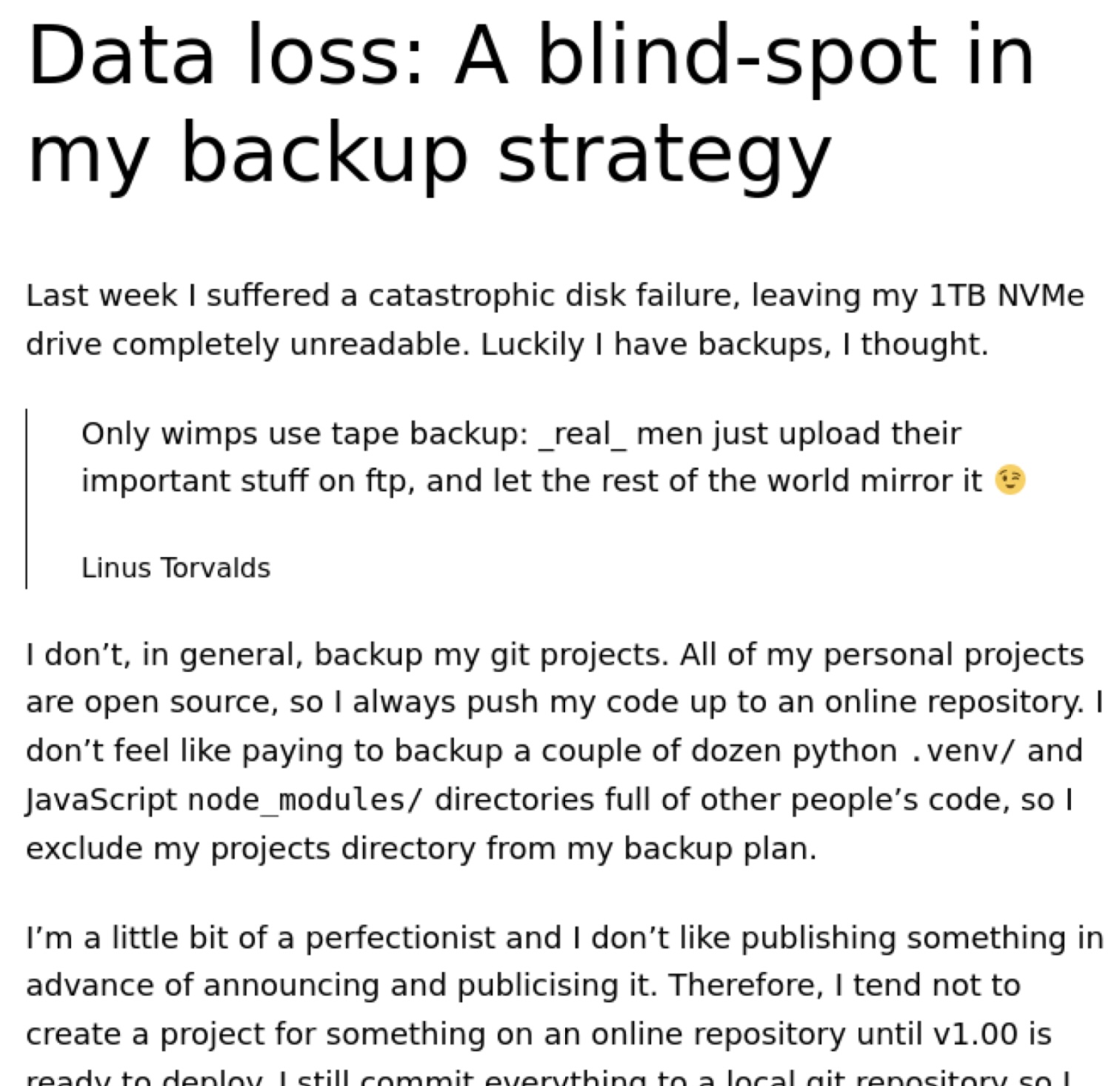

This is another recent post and the equivalent page presented to LLM bots.


In both of these examples, all of the HTML tags are lost. Formatting, links and images are all stripped and just paragraphs of text are returned.
How does it work?
We grab the text content of the upstream pages, parse out each sentence on the page, then build a list of word-pairs that make up each sentence. We use None to signify the start and end of a sentence. Taking the simple sentence,
“this is the only sentence”,
we can split it into the following word-pairs.
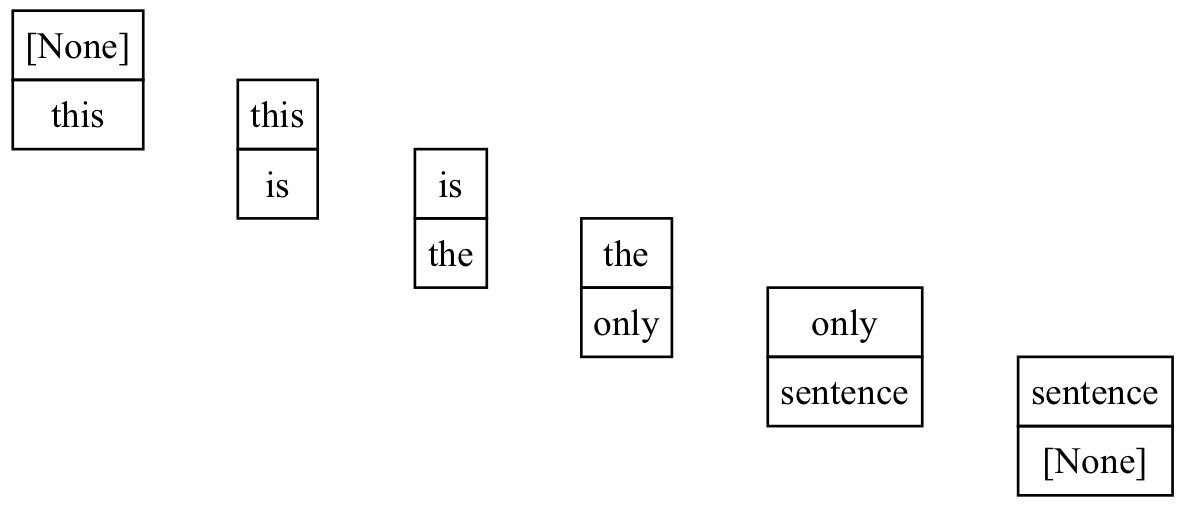
If we treat these word-pairs like cons cells or tree nodes, we can build a graph that indicates the reading flow through the sentence.
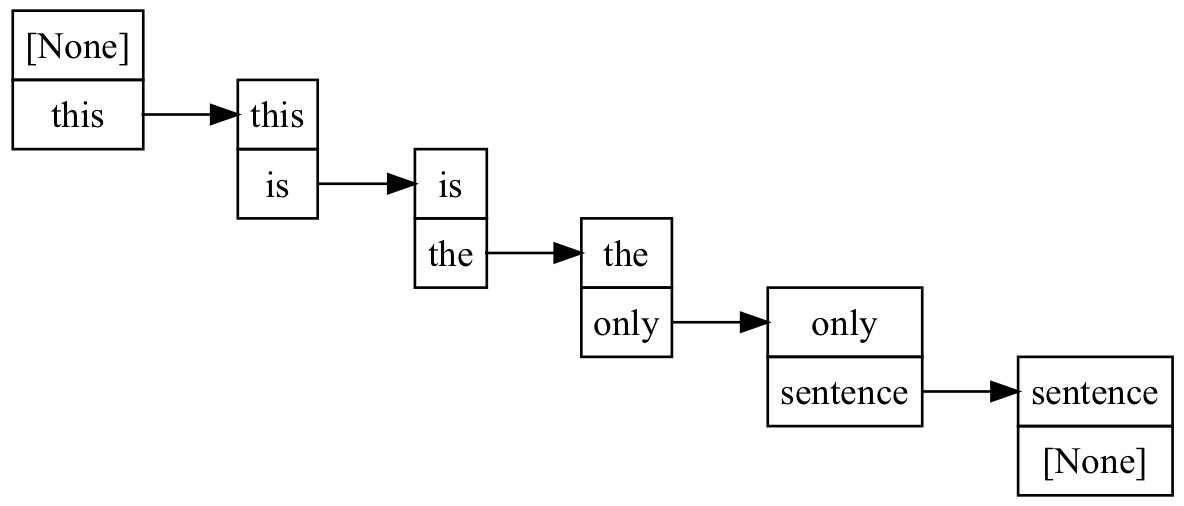
Simplifying this by removing the duplicated information, we get the following, much more readable, graph.

Following the flow through the word-pairs we can see that “this is the only sentence” is the only sentence an algorithm could generate from this graph.
Creating another graph, this time based on a single sentence but with one word repeated in a couple of places,
“this is the sentence that might have the loop“,
we can see there are more options for the algorithm to follow.

In addition to the input text, “this is the sentence that might have the loop”, we can see that the algorithm could take a shortcut and skip the loop returning, “this is the loop”. It could also generate an infinite number of extended sentences by running round the loop several times before exiting, producing something like “this is the sentence that might have the sentence that might have the sentence that might have the sentence that might have the loop”.
If we feed the algorithm two sentences that share a single word,
“this is the only sentence” and
“only word that matters”,
we can see there are four paths through the graph.

The algorithm could therefore produce not only the two original input sentences, but two completely new ones, “only sentence” and “this is the only word that matters”.
Taking things further, here’s a graph built from an entire paragraph of one of my #NewMusicMonday posts.
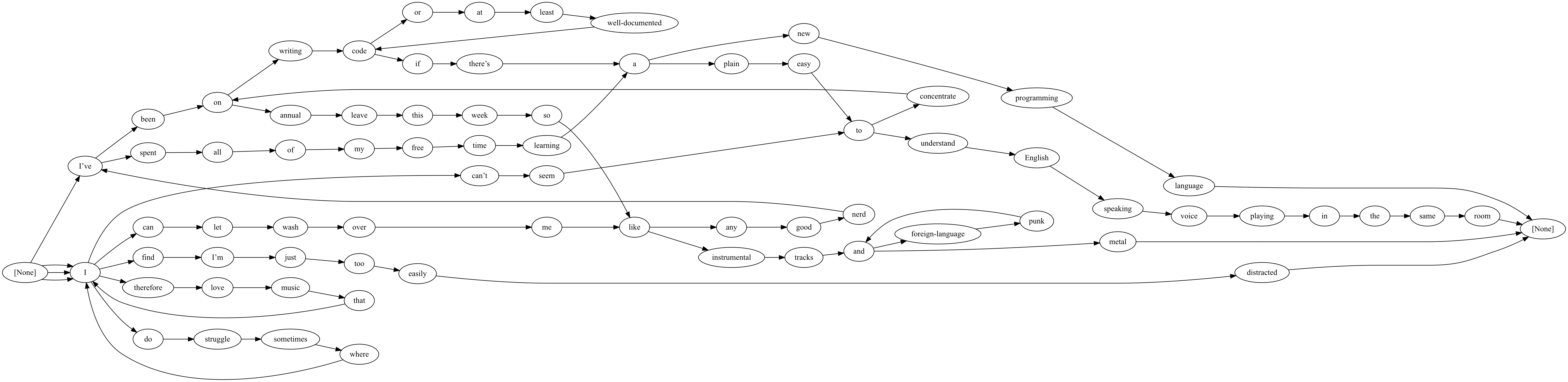
With my tongue firmly lodged in my cheek, I like to refer to these graphs as little language models, or maybe wee language models depending on which side of the border you are.
See it in action
At the moment, I don’t have fully working copy running in front of my site, I’ve instead got it installed on my app server at https://poisoned.mikecoats.xyz. Since we only rewrite text not HTML, including a tags, you won’t be able to follow and of the links there, so instead here’s three pages that are being served through the reverse-proxy.
- https://poisoned.mikecoats.xyz/aa-sms/
- https://poisoned.mikecoats.xyz/a-blind-spot-in-my-backup-strategy/
- https://poisoned.mikecoats.xyz/newmusicmonday-mwwb-slomatics/
If you have a browser extension that lets you alter your user-agent, such as User-Agent Switcher and Manager for Firefox, visiting those links with an agent string like ClaudeBot or GPTBot should give you the hallucinated versions. A visit with your normal user-agent will give you the regular content. If you’re on a platform, or use a browser, where user-agent spoofing is not possible the following links will take you directly to the hallucinations.
- https://bot-view.poisoned.mikecoats.xyz/aa-sms/
- https://bot-view.poisoned.mikecoats.xyz/a-blind-spot-in-my-backup-strategy/
- https://bot-view.poisoned.mikecoats.xyz/newmusicmonday-mwwb-slomatics/
There are still some rough edges around the text and sentence parsers that would improve the quality of the output, and I’ve spotted some server errors crop up from time to time, so it’s not finished but I think it’s good enough to show off.
The code is available from my git repository and it includes some quite terrible installation instructions if you want to play with it yourself. Right now I’ve only got configuration files that integrate with Caddy, but I’m looking in to Nginx and Apache versions too.
The application is free software so you can redistribute it and/or modify it under the terms of the GNU Affero General Public License as published by the Free Software Foundation, either version 3 of the License, or (at your option) any later version. The configuration files are released under the MIT License as they’re based on a JSON file from Cory Dransfeldt’s upstream ai.robots.txt repository.
2024-08-12